Some time ago, I have explored the mobile deployment space domain a bit, by implementing a function capable of building Android Apps with the Nix package manager. However, Android is definitely not the only platform used in the mobile space. Another major one is Apple's iOS, used by mobile devices, such as the iPhone, iPod, and iPad. In this blog post, I describe how I have implemented a Nix function capable of building Apps for these platforms.
Although it was quite some work to package the Android SDK, it took me less work for iOS. However, all prerequisites for this platform cannot be entirely packaged in Nix, due to the fact that they require Xcode, that must be installed through the App store, and it has all kinds of implicit assumptions on the system (such as location of certain tools and binaries), which prevents all required components to be packaged purely. Therefore, I had to use similar "tricks" that I have used to allow .NET applications to be deployed through the Nix package manager.
The first dependency that requires manual installation is Apple's Xcode, providing a set of development tools and an IDE. It must be obtained from the App store through the following URL: https://developer.apple.com/xcode. The App store takes care of the complete installation process.
After installing Xcode, we must also manually install the command-line utilities. This can be done by starting Xcode, picking the preferences option from the 'Xcode' menu bar, selecting the 'Downloads' tab in the window and then by installing the command-line utilities, as shown in the screenshot below:
![]()
An Xcode installation includes support for the most recent iOS versions by default. If desired, SDKs for older versions can be installed through the same dialog.
To use the Nix package manager, we can either download a collection of bootstrap binaries or we can compile it from source. I took the latter approach for which it is required to install a number of prerequisites through MacPorts. Installation of MacPorts is straight forward -- it's just downloading the installer from their website (for the right Mac OS X version) and running it.
To install Nix from source code, I first had to install a bunch of dependencies through MacPorts. I opened a terminal and I've executed the following commands:
In order to package iOS applications, we have to make the Xcode build infrastructure available to Nix package builds. However, as explained earlier, we cannot package Xcode in Nix, because it must be installed through other means (through Apple's App store) and it has a number of assumptions on locations of utilities on the host system.
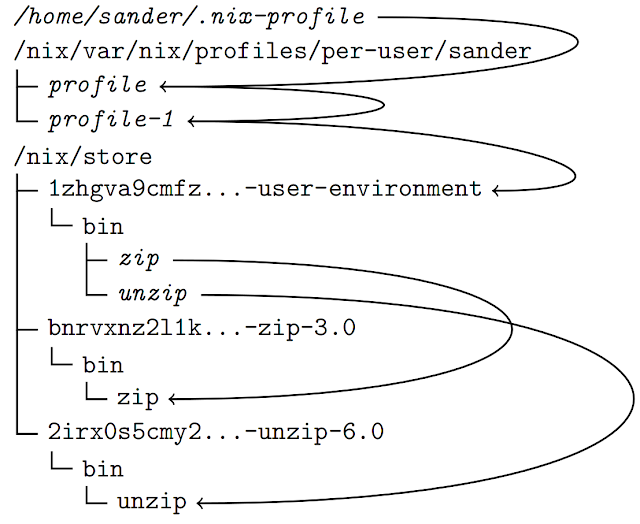
Instead we use the same trick that we have used earlier for the .NET framework -- we create a proxy component wrapper that contains symlinks to essential binaries on the host system. Our xcodewrapper package expression looks as follows:
Furthermore, the expression contains a check that verifies whether the installed Xcode matches the version that we want to use, ensuring that -- if we upgrade Xcode -- we use the version that we want, and that everything that has Xcode as build-time dependency gets rebuilt, if necessary.
By adding the xcodewrapper to the buildInputs parameter of a package expression, the Xcode build utilities can be found and used.
Getting Xcode working in Nix is a bit ugly and does not provide full reproducibility as Xcode must be installed manually, but it works. Another important question to answer is, how do we build iOS apps with Nix?
Building iOS apps is pretty straight forward, by running xcodebuild inside an Xcode project directory. The xcodebuild reference served as a good reference for me. The following instruction suffices to build an app for the iPhone simulator:
Building actual releases for Apple devices is a bit trickier though. In order to deploy an App to a Apple device, a distribution certificate is required as well as an provisioning profile. To test on an Apple device, an ad-hoc provisioning profile is required. For the App store, you need a distribution profile. These files must be obtained from Apple. More information on this can be found here.
Furthermore, in order to use a certificate and provisioning profile, we need to import these into the keychain of the user that executes a build. I use the following instructions to automatically create and unlock a new keychain:
After creating the keychain, we must import our certificate into it. The following instruction imports a key with the name mykey.p12 into the keychain with name: mykeychain and uses the password: secret for the certificate (the -A parameter grants all applications access to the certificate):
To test an app on an Apple device, we must generate an IPA file, a Zip archive containing all files belonging to an App. This can be done by running:
In order to release an App through the Apple App store, we must generate an xcarchive, a zip archive that also contains debugging symbols and plist files. An xcarchive can be generated by adding the archive parameter to xcodebuild. The resulting xcarchive is automatically added to the Xcode organiser.
If the build process has been completed, we can eventually remove our keychain:
We can also script the iPhone simulator to automatically start an App produced by xcodebuild, for a particular iOS device:
![]()
To demonstrate how the iOS deployment functions work, I have implemented the trivial 'Hello world' example case described in Apple's iOS tutorial. It was also a nice exercise to get myself familiar with Xcode and Objective C development.
Apart from implementing the example case, I have made two extensions:
I have encapsulated the earlier described build steps in a Nix function called: xcodeenv.buildApp. To build the Hello World example for the simulator, one could write the following expression:
To make a build for release, the following expression can be written:
The function invocation above conveniently takes care of the build, key signing and packaging process, although there were two nasty caveats:
As with ordinary Nix expressions, we cannot use the previous two expressions to build an App directly, but we also need to compose them by calling them with the right xcodeenv parameter. This is done in the following composition expression:
If we take the composition expression (shown earlier), we also see a simulator attribute: simulate_helloworld_iphone, which we can evaluate to generate a script launching a simulator for the iPhone. By executing the generated script we launch the simulator:
![]()
In addition to the iPhone, I have also developed a function invocation simulating the iPad (as can be seen in the composition expression, shown earlier):
![]()
In this blog post, I have described two Nix functions that allow users to automatically build, sign and package iOS applications and to run these in an iPhone simulator instance.
Although the Nix functions seems to work, they are still highly experimental, have some workarounds (such as the key signing) and are not entirely pure, due to the fact that it requires Xcode which must be installed through Apple's App store.
I have conducted these experiments on a Mac OS X 10.7.5 (Lion) machine. Mac OS X 10.8 Mountain Lion, is also reported to work.
I'd like to thank my colleagues Mathieu Gerard (for showing me the keysigning command-line instructions) and Alberto Gonzalez Sanchez (for testing this on Mac OS X Mountain Lion) from Conference Compass.
This function is part of Nixpkgs. The example case can be obtained from my github page.
Although it was quite some work to package the Android SDK, it took me less work for iOS. However, all prerequisites for this platform cannot be entirely packaged in Nix, due to the fact that they require Xcode, that must be installed through the App store, and it has all kinds of implicit assumptions on the system (such as location of certain tools and binaries), which prevents all required components to be packaged purely. Therefore, I had to use similar "tricks" that I have used to allow .NET applications to be deployed through the Nix package manager.
Installing Xcode
The first dependency that requires manual installation is Apple's Xcode, providing a set of development tools and an IDE. It must be obtained from the App store through the following URL: https://developer.apple.com/xcode. The App store takes care of the complete installation process.
After installing Xcode, we must also manually install the command-line utilities. This can be done by starting Xcode, picking the preferences option from the 'Xcode' menu bar, selecting the 'Downloads' tab in the window and then by installing the command-line utilities, as shown in the screenshot below:

An Xcode installation includes support for the most recent iOS versions by default. If desired, SDKs for older versions can be installed through the same dialog.
Installing MacPorts
To use the Nix package manager, we can either download a collection of bootstrap binaries or we can compile it from source. I took the latter approach for which it is required to install a number of prerequisites through MacPorts. Installation of MacPorts is straight forward -- it's just downloading the installer from their website (for the right Mac OS X version) and running it.
Installing the Nix package manager
To install Nix from source code, I first had to install a bunch of dependencies through MacPorts. I opened a terminal and I've executed the following commands:
I have obtained the source tarball of Nix from the Nix homepage, and I have installed it from source by running the following command-line instructions:
$ sudo port install sqlite3
$ sudo port install pkgconfig
$ sudo port install curl
$ sudo port install xz
Furthermore, I was a bit lazy and I only care about using a single-user installation. To use Nix as a non-root user I ran the following command to change the permissions to my user account:
$ tar xfvj nix-1.1.tar.bz2
$ cd nix-1.1
$ ./configure
$ make
$ sudo make install
For development, it's also useful to have a copy of Nixpkgs containing expressions for many common packages. I cloned the git repository, by running:
sudo chown -R sander /nix
To conveniently access stuff from the Nix packages repository, it is useful to add the following line to the ~/.profile file so that they are in Nix's include path:
$ git clone https://github.com/NixOS/nixpkgs.git
I also added channels that provides substitutes for builds performed at our build infrastructure, so that I don't have to compile everything from source:
$ export NIX_PATH=nixpkgs=/path/to/nixpkgs
$ nix-channel --add http://nixos.org/releases/nixpkgs/channels/nixpkgs-unstable
$ nix-channel --update
"Packaging Xcode" in Nix
In order to package iOS applications, we have to make the Xcode build infrastructure available to Nix package builds. However, as explained earlier, we cannot package Xcode in Nix, because it must be installed through other means (through Apple's App store) and it has a number of assumptions on locations of utilities on the host system.
Instead we use the same trick that we have used earlier for the .NET framework -- we create a proxy component wrapper that contains symlinks to essential binaries on the host system. Our xcodewrapper package expression looks as follows:
Basically, the following expression contains a number of symlinks to essential Xcode binaries:
{stdenv}:
let
version = "4.5.2";
in
stdenv.mkDerivation {
name = "xcode-wrapper-"+version;
buildCommand = ''
ensureDir $out/bin
cd $out/bin
ln -s /usr/bin/xcode-select
ln -s /usr/bin/xcodebuild
ln -s /usr/bin/xcrun
ln -s /usr/bin/security
ln -s "/Applications/Xcode.app/Contents/Developer/Platforms/iPhoneSimulator.platform\
/Developer/Applications/iPhone Simulator.app/Contents/MacOS/iPhone Simulator"
# Check if we have the xcodebuild version that we want
if [ -z "$($out/bin/xcodebuild -version | grep ${version})" ]
then
echo "We require xcodebuild version: ${version}"
exit 1
fi
'';
}
- xcode-select is a utility to determine filesystem location of Xcode, or to switch between default versions.
- xcodebuild is a command-line utility to build Xcode projects.
- xcrun is a utility to execute specific Xcode-specific operations, such as packaging a build result.
- security is a command-line interface to Mac OS X's keychain facility that manages security certificates and identities.
- iPhone Simulator. A program to simulate iOS applications on the host system.
Furthermore, the expression contains a check that verifies whether the installed Xcode matches the version that we want to use, ensuring that -- if we upgrade Xcode -- we use the version that we want, and that everything that has Xcode as build-time dependency gets rebuilt, if necessary.
By adding the xcodewrapper to the buildInputs parameter of a package expression, the Xcode build utilities can be found and used.
Building iOS apps for the simulator
Getting Xcode working in Nix is a bit ugly and does not provide full reproducibility as Xcode must be installed manually, but it works. Another important question to answer is, how do we build iOS apps with Nix?
Building iOS apps is pretty straight forward, by running xcodebuild inside an Xcode project directory. The xcodebuild reference served as a good reference for me. The following instruction suffices to build an app for the iPhone simulator:
The above command-line instruction builds an app for the i386 architecture (Apps in the simulator have the same architecture as the host system) using the iPhone 6.0 simulator SDK. The last two parameters ensure that intermediate files generated by the compiler are stored in our temp directory and that the resulting build is stored in our desired prefix, instead of the Xcode project directory.
$ xcodebuild -target HelloWorld -configuration Debug \
-sdk iphonesimulator6.0 -arch i386 ONLY_ACTIVE_ARCH=NO \
CONFIGURATION_TEMP_DIR=$TMPDIR CONFIGURATION_BUILD_DIR=$out
Building iOS apps for release
Building actual releases for Apple devices is a bit trickier though. In order to deploy an App to a Apple device, a distribution certificate is required as well as an provisioning profile. To test on an Apple device, an ad-hoc provisioning profile is required. For the App store, you need a distribution profile. These files must be obtained from Apple. More information on this can be found here.
Furthermore, in order to use a certificate and provisioning profile, we need to import these into the keychain of the user that executes a build. I use the following instructions to automatically create and unlock a new keychain:
The above instructions generate a keychain with the name mykeychain in the user's home directory: ~/Library/Keychains.
$ security create-keychain -p "" mykeychain
$ security default-keychain -s mykeychain
$ security unlock-keychain -p "" mykeychain
After creating the keychain, we must import our certificate into it. The following instruction imports a key with the name mykey.p12 into the keychain with name: mykeychain and uses the password: secret for the certificate (the -A parameter grants all applications access to the certificate):
We must also make the provisioning profile available. This can be done by extracting the UUID from the mobile provisioning file and to copy the file into ~/Library/MobileDevice/Provisioning Profiles/<UUID>.mobileprovision:
$ security import mykey.p12 -k mykeychain -P "secret" -A
After importing the certificate and provisioning files, we can invoke xcodebuild to build a release App using the earlier certificate and provisioning profile (I have based this invocation on a Stack overflow post about setting a provisioning profile):
PROVISIONING_PROFILE=$(grep UUID -A1 -a myprovisioningprofile.mobileprovision | \
grep -o "[-A-Z0-9]\{36\}")
mkdir -p "$HOME/Library/MobileDevice/Provisioning Profiles"
cp myprovisioningprofile.mobileprovision \
"$HOME/Library/MobileDevice/Provisioning Profiles/$PROVISIONING_PROFILE.mobileprovision"
The above command-line invocation is nearly identical to the one that builds an App for the simulator, except that we have a different SDK parameter: iphoneos6.0, and the armv7 architecture. Moreover, we have to specify the identity name of the key, and the locations of the provisioning profiles and keychains.
$ xcodebuild -target HelloWorld -configuration Release \
-sdk iphoneos6.0 -arch armv7 ONLY_ACTIVE_ARCH=NO \
CONFIGURATION_TEMP_DIR=$TMPDIR CONFIGURATION_BUILD_DIR=$out \
CODE_SIGN_IDENTITY="My Cool Company" \
PROVISIONING_PROFILE=$PROVISIONING_PROFILE \
OTHER_CODE_SIGN_FLAGS="--keychain $HOME/Library/Keychains/mykeychain"
To test an app on an Apple device, we must generate an IPA file, a Zip archive containing all files belonging to an App. This can be done by running:
By using the Xcode organiser the given App can be uploaded to an Apple device.
$ xcrun -sdk iphoneos PackageApplication \
-v HelloWorld.app -o HelloWorld.ipa
In order to release an App through the Apple App store, we must generate an xcarchive, a zip archive that also contains debugging symbols and plist files. An xcarchive can be generated by adding the archive parameter to xcodebuild. The resulting xcarchive is automatically added to the Xcode organiser.
If the build process has been completed, we can eventually remove our keychain:
$ security delete-keychain mykeychain
Simulating iOS applications
We can also script the iPhone simulator to automatically start an App produced by xcodebuild, for a particular iOS device:
The above command launches an iPhone instance running our simulator build performed earlier. The former command-line option refers to the executable that we have built. The latter specifies the type of device we want to simulate. Other device options that worked for me are: 'iPad', 'iPad (Retina)', 'iPhone (Retina 3.5-inch)', 'iPhone (Retina 4-inch)'.
"iPhone Simulator" -SimulateApplication build/HelloWorld \
-SimulateDevice 'iPhone'
Implementing a test case

To demonstrate how the iOS deployment functions work, I have implemented the trivial 'Hello world' example case described in Apple's iOS tutorial. It was also a nice exercise to get myself familiar with Xcode and Objective C development.
Apart from implementing the example case, I have made two extensions:
- The example only implements the iPhone storyboard. On the iPad, it shows me an empty screen. I also implemented the same stuff in the iPad storyboard to make it work smoothly on the iPad.
- In order to pass the validation process for releases, we need to provide icons. I added two files: Icon.png (a 59x59 image) and Icon-72.png (a 72x72 image) and I added them to the project's info.plist file.
Deploying iOS applications with Nix
I have encapsulated the earlier described build steps in a Nix function called: xcodeenv.buildApp. To build the Hello World example for the simulator, one could write the following expression:
The function is very simple -- it invokes the xcodeenv.buidApp function and takes three parameters: name is the name of the xcode project, src is a path referring to the source code and release indicates whether we want to build for release or not. If release is false, then it will build the app for the simulator. It also assumes that the architecture (arch) is i386 and the SDK is the iphonesimulator, which is usually the case. These parameters can be overridden by adding them to the function parameters of the function invocation.
{xcodeenv}:
xcodeenv.buildApp {
name = "HelloWorld";
src = ../../src/HelloWorld;
release = false;
}
To make a build for release, the following expression can be written:
The above expression sets the release parameter to true. In this case, the architecture is assumed to be armv7 and the SDK iphoneos, which ensures that the App is build for the right architecture for iOS devices. For release builds we also need to specify the certificate, provisioning profile, and their relevant properties. Furthermore, we can also specify whether we want to generate an IPA (an archive to deploy an App to a device) or xcarchive (an archive to deploy an App to Apple's App store).
{xcodeenv}:
xcodeenv.buildApp {
name = "HelloWorld";
src = ../../src/HelloWorld;
release = true;
certificateFile = /Users/sander/mycertificate.p12;
certificatePassword = "secret";
codeSignIdentity = "iPhone Distribution: My Cool Company";
provisioningProfile = /Users/sander/provisioningprofile.mobileprovision;
generateIPA = false;
generateXCArchive = false;
}
The function invocation above conveniently takes care of the build, key signing and packaging process, although there were two nasty caveats:
- To ensure purity, Nix restricts access to the user's home directory by setting the HOME environment variable to /homeless-shelter. For some operations that require a home directory, it suffices to set HOME to a temp directory. This seems not to work for key signing on Mac OS X. Generating a keychain and importing a certificate seems to work fine, but signing does not. I suspect this has something to do with the fact that the keychain is a system service.
I have circumvented this issue by generating a keystore in the real user's home directory, with exactly the same name as the Nix component name that we are currently building, including the unique hash derived from the build inputs. The hash should ensure that the name never interferes with other components. Furthermore, the keychain is always removed after the build, whether it succeeds or not. This solution is a bit nasty and tricky, but it works fine for me and should not affect an existing build, running simultaneously. - Another caveat is the generation of xcarchives. It works fine, but the result is always stored in a global location: ~/Library/Developer/Xcode/Archives that allows the Xcode organiser to find it. It looks like there is no way to change this. Therefore, I don't know how to make the generation of xcarchives pure, although this is a task that only needs to be performed when releasing an App through Apple's App store. This task is typically performed only once in a while.
As with ordinary Nix expressions, we cannot use the previous two expressions to build an App directly, but we also need to compose them by calling them with the right xcodeenv parameter. This is done in the following composition expression:
By using the expression above and by running nix-build, we can automatically build an iOS app:
rec {
xcodeenv = import ...
helloworld = import ./pkgs/helloworld {
inherit xcodeenv;
};
simulate_helloworld_iphone = import ./pkgs/simulate-helloworld {
inherit xcodeenv helloworld;
device = "iPhone";
};
simulate_helloworld_ipad = import ./pkgs/simulate-helloworld {
inherit xcodeenv helloworld;
device = "iPad";
};
...
}
Besides build an App, we can also write an expression to simulate an iOS app:
$ nix-build default.nix -A hello
/nix/store/0nlz31xb1q219qrlmimxssqyallvqdyx-HelloWorld
$ cd result
$ ls
HelloWorld.app HelloWorld.app.dSYM
The above expression calls the xcodeenv.simulateApp function that generates a script launching the iPhone Simulator. The name parameter corresponds to the name of the App, the app parameter refers to a simulator build of an App, an the device parameter specifies the device to simulate, such as an iPhone or iPad.
{xcodeenv, helloworld, device}:
xcodeenv.simulateApp {
name = "HelloWorld";
app = helloworld;
inherit device;
}
If we take the composition expression (shown earlier), we also see a simulator attribute: simulate_helloworld_iphone, which we can evaluate to generate a script launching a simulator for the iPhone. By executing the generated script we launch the simulator:
Which shows me the following:
$ nix-build -A simulate_helloworld_iphone
$ ./result/bin/run-test-simulator

In addition to the iPhone, I have also developed a function invocation simulating the iPad (as can be seen in the composition expression, shown earlier):
And this is the result:
$ nix-build -A simulate_helloworld_ipad
$ ./result/bin/run-test-simulator

Conclusion
In this blog post, I have described two Nix functions that allow users to automatically build, sign and package iOS applications and to run these in an iPhone simulator instance.
Although the Nix functions seems to work, they are still highly experimental, have some workarounds (such as the key signing) and are not entirely pure, due to the fact that it requires Xcode which must be installed through Apple's App store.
I have conducted these experiments on a Mac OS X 10.7.5 (Lion) machine. Mac OS X 10.8 Mountain Lion, is also reported to work.
I'd like to thank my colleagues Mathieu Gerard (for showing me the keysigning command-line instructions) and Alberto Gonzalez Sanchez (for testing this on Mac OS X Mountain Lion) from Conference Compass.
This function is part of Nixpkgs. The example case can be obtained from my github page.